
CF Webtools has maintained VMWare ESXi guest OS instances, managed by vCenter, for about 7 years. They are a mix of Linux and Windows Server OSs and are maintained at a secure and redundant co-location data center. While an expensive up-front investment, it has paid for itself over those years, and we have a plan to continue that solution for about another 5 years. A recent upgrade to the next major version proved that virtual machines take a fraction of time for maintenance compared to bare metal instances. Granted, there’s some spin-up time when things work for so long, and you must remember, research, and troubleshoot procedures. Managed cloud takes almost all that time out of the equation, making it my favorite. Though I do miss hands-on hardware here and there.
Some of our on-prem VMs are critical, and some are not. The critical ones have always been backed up with different solutions, depending upon what they are and what the recovery needs look like. However, almost all have come with challenges. So I wanted to look for a VM snapshot-based cloud backup solution that I could trust and would be budget-friendly.
My first direction was to research Veeam. Their solution is very well known. However, it was a struggle to get the attention of Veeam and CDW as a small business without an existing account. I was able to lean on one of our hardware vendors, xByte, who hooked us up with one of their Veeam partners. But it was determined that it was fairly costly with a per-instance license model compared to our existing solutions. So I continued my search.
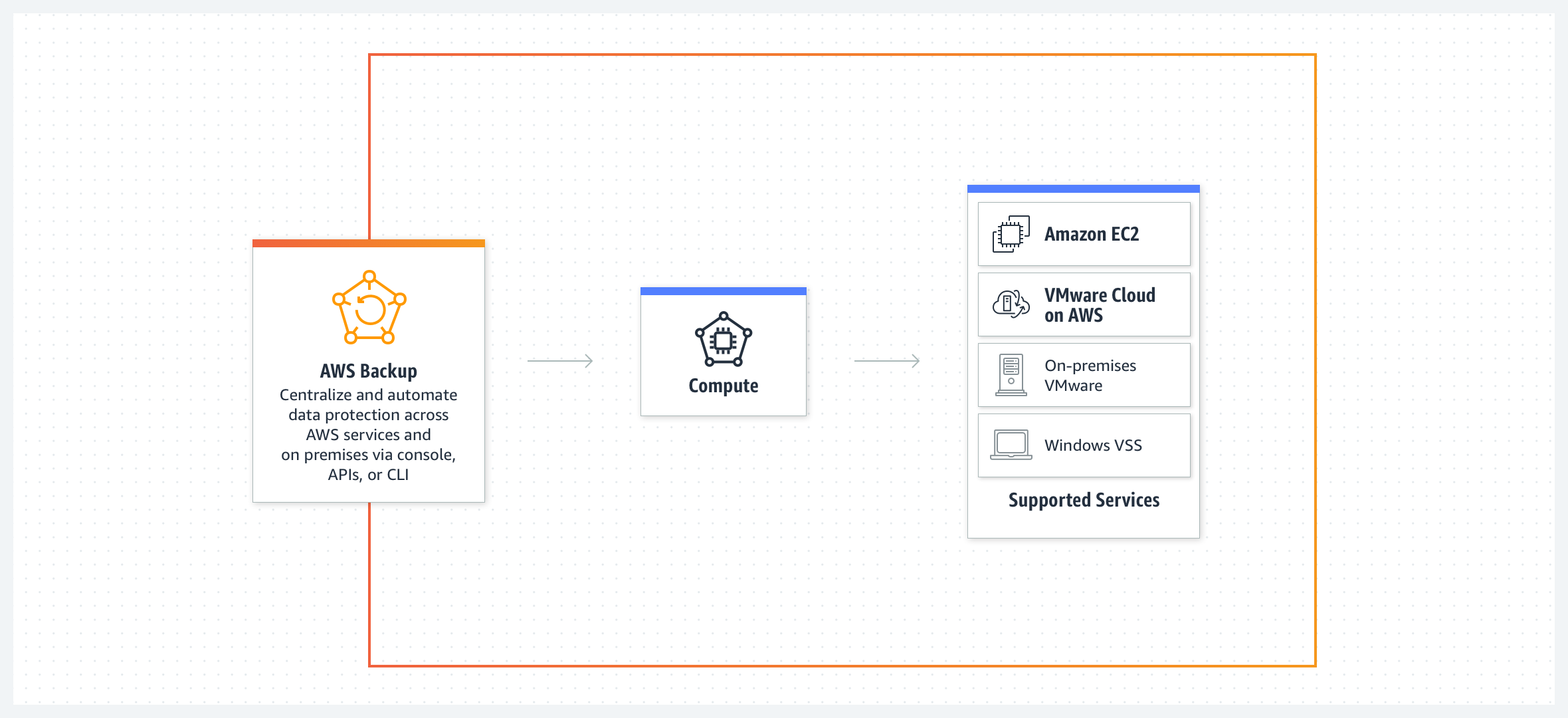
I then found AWS Backup has an on-prem VMWare solution. AWS Backup is relatively new to the backup game, but its implementations are continually growing. We currently use that service for all our AWS EC2 backups. That service was a “God send” after numerous awful implementations of custom Lambda/CloudWatch scripts and an EBS Automation method. Finally, a solution for what should have been around since the start of EC2.
As of November 2021, AWS Backup offers backup for on-prem VMWare vCenter servers. You must install their Storage Gateway virtual appliance as the “middleman” agent. I was hoping for an “agentless” solution; however, we only pay $0.05/GB-Mo warm storage and $0.01/GB-Mo Cold Storage. That’s a considerable saving, considering we do not have to pay for a license per instance, and there are no incoming bandwidth fees! We will have to pay bandwidth for on-prem restores, but considering that is very rarely done, and bandwidth is relatively cheap, it’s a non-issue. We’d have to pay for storage anyway, so there’s no change.
Another significant advantage is we get a single backup solution for both on-prem and AWS Cloud. It’s one less piece of software we must be familiar with, document, troubleshoot, and keep updated. Outside of an office domain controller, we also anticipate a complete cutover to AWS in 5 years.
We have successfully installed the storage gateway and started backing up instances as a test. Everything seems to be going very smoothly. I must transition from a static list of protected resources to a tag-based backup system. Unfortunately, to remove or add an instance to the static list, you must delete and recreate the list. This is not very friendly. However, if the tags are managed on the VM itself, it will be a much better solution. I could back up everything a just create an exclusion pattern. However, I plan to make the backups immutable for a few years to protect against ransomware. Therefore, I don’t want temporary or “mistake” instances saved for a few years. However, if the ransomware or malware ever gets ahold of the instance tags, we could potentially stop backing up instances without knowing. So it’s something I need to consider, research, and plan.
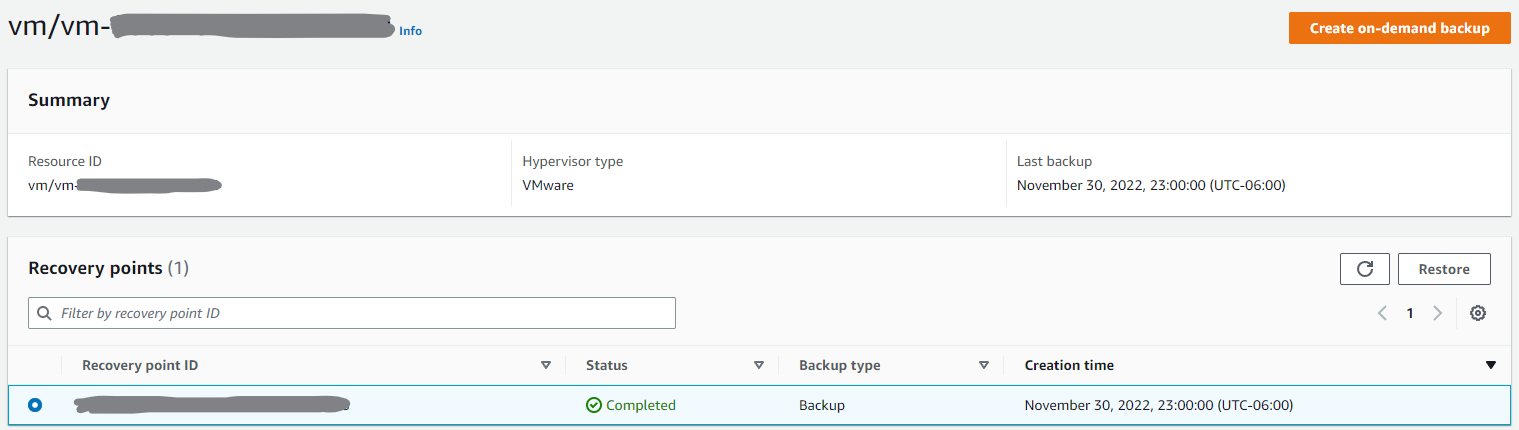
That being said, we needed to restore an instance the other day to grab a corrupted folder. However, the restore process “phase” hasn’t been researched, documented, or tested yet, and it was a mess. Every article out there shows how to configure the backups. But none are worth anything in terms of how to restore. The UI restore process is very manual.
First, your “Protected resources” list, backup plan resource list, jobs list, and backup vault recovery point list are by Resource ID only. Not by a human-readable name. To understand what you want to verify or restore, you must go to the “Virtual Machines” screen, which will show you the list of VM names (human-readable). From there, you can click on the name, go the the “Recovery points” section, and press “Restore”
But here is where it gets annoying. The “Restore Location”, “Hypervisor”, “Virtual machine name”, and likely the “Compute resource” are apparent. For the Datastore, I am uncertain if it wants the label such as “Drive Array 1” or if it needs something more robotic like “drive_array_1” found in the CLI. But where I was hanging up at was the “Path”. I was getting “”Invalid folder detected during virtual machine creation. Aborted restore job”. All I got for an answer to this was, “use your organization’s virtual machine best practices”.
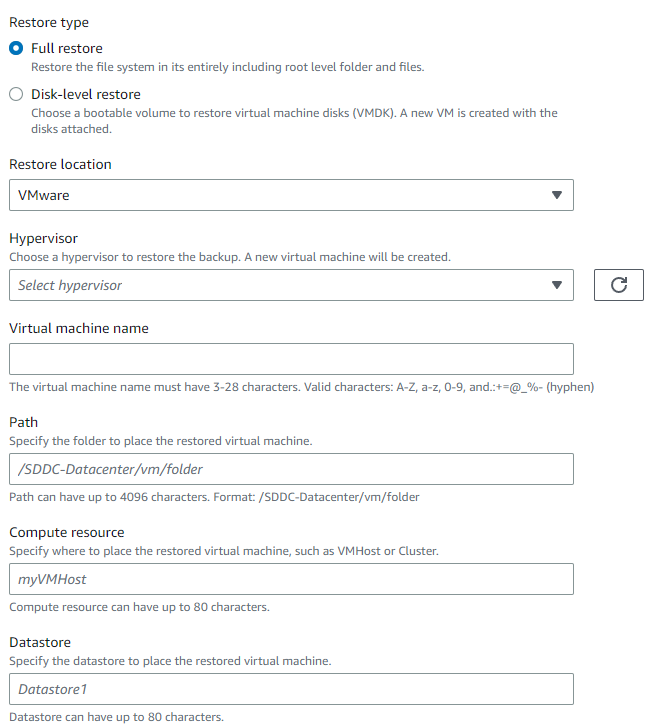
However, I happened upon the proper data to fill in via trial and error:
- Full restore / Disk-level restore: “Full Restore”. I am uncertain what the differences are here, other than you can be selective of the volumes to restore. At this time, I’m always going with “Full Restore”.
- Restore location: VMware
- Hypervisor: Your connected Hypervisor is listed under “Hypervisors” in the “External resources” menu group. Example:
vcenter1.ad.cfwebtools - Virtual Machine Name: The new name of the Guest VM to restore to. As far as I’m aware, this must be a new VM rather than overwriting the originating guest VM. Example:
Web Server 1 - Path: Go to
AWS Backup>External resources>Virtual machines. Use the “Path” value listed for the associated originating VM. Example:/DataCenter1/vm - Compute resource: The ESXi host FQDN or IP listed under the datacenter grouping in the vCenter Web Client. Example:
esxi2.ad.cfwebtools - Datastore: The name label used under the “Datastores” tab in the vSphere Client for that host (compute resource). Example:
Storage Array 1
This information should fill in the gaps needed for a restore from AWS Backup to on-prem VMWare vCenter. I look forward to AWS enhancing its UI. It would be good to see cross-referenced name labels, percentage complete status, and estimated times.
One thing I have noted is “failed” status backup jobs. As they are only referenced by a “Resource ID”, such as vm/vm-000103A5502847AB, and they are marked as “The virtual machine is not found”. I have no idea what I’m missing without extensive research. The Resource ID is no longer listed in “Virtual Machines” to cross-reference the name label. So now begs the question, if I lose my VMs, they are no longer listed in “Virtual Machines”. How would I know which one to restore? I may have to start a spreadsheet, and that’s counterproductive!
Note that the “Backup size” listed in Jobs is not the actual data size backed up. Each snapshot will have just the blocks changed since the last snapshot. That may be more or less, in sum, than the listed size. In addition, that size is the fully reserved disk size. The actual data is smaller.
For example, I restored an 85GB listed instance. When in reality, the thin provision was about 5.4GB. That restore took about 4 minutes. An additional reference is a listed 120GB restore job, whose thin provision is about 100GB, which took about 1.25 hours to restore and convert into an EC2 instance. The EC2 instance worked flawlessly to gather the files I needed.
I look forward to learning more about AWS Backup and will update this article as I test and learn more.
